How Do You Know if Something Is Getting Down Voted on Reddit
Terminal calendar month, Storybench editor Aleszu Bajak and I decided to explore user data on nootropics, the brain-boosting pills that have become popular for their productivity-enhancing properties. Many of the substances are likewise banned past at the Olympics, which is why nosotros were able to pitch and publish the piece at Smithsonian magazine during the 2018 Winter Olympics. For the story and visualization, we decided to scrape Reddit to ameliorate sympathise the churr surrounding drugs similar modafinil, noopept and piracetam.
In this Python tutorial, I will walk you through how to access Reddit API to download data for your own project.
This is what you volition demand to become started:
- Python three.10: I recommend you use the Anaconda distribution for the simplicity with packages. You can also download Python from the project's website. When following the script, pay special attention to indentations, which are a vital part of Python.
- An IDE (Interactive Evolution Environment) or a Text Editor: I personally use Jupyter Notebooks for projects like this (and it is already included in the Anaconda pack), just apply what you are almost comfortable with. You can also run scripts from the command-line.
- These two Python packages installed: Praw, to connect to the Reddit API, and Pandas, which we volition use to handle, format, and export data.
- A Reddit business relationship. You tin create it here.
The Reddit API
The very offset thing you'll need to do is "Create an App" inside Reddit to become the OAuth2 keys to access the API. Information technology is easier than you lot think.
Go to this page and click create app or create another app button at the bottom left.
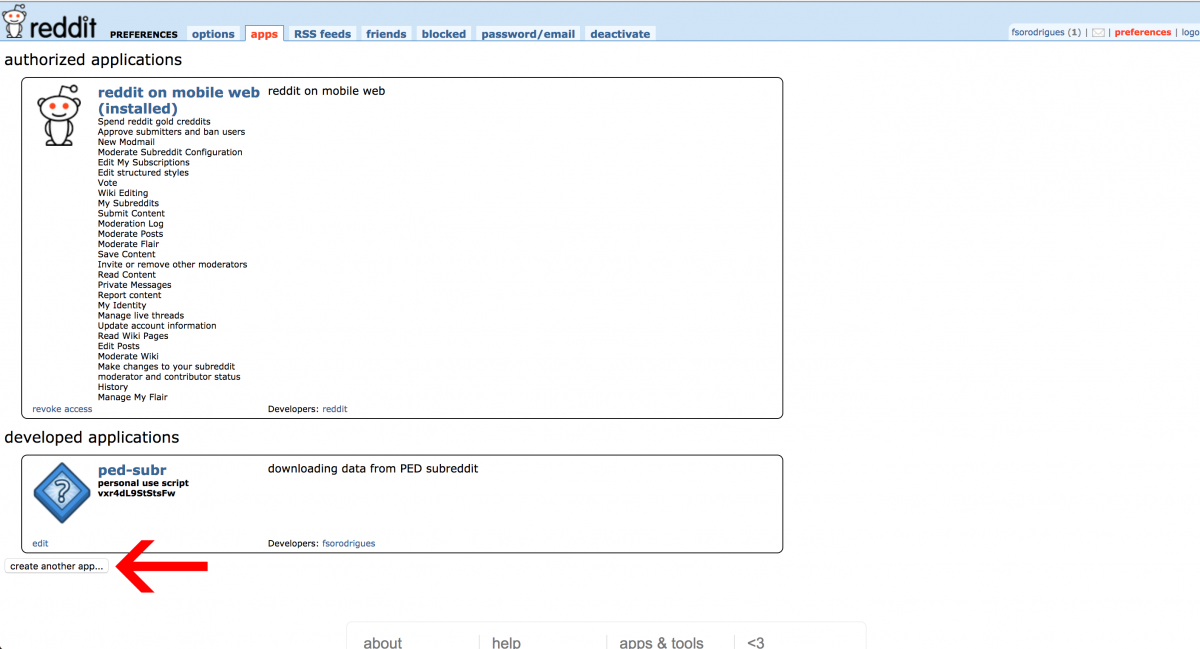
This form volition open.
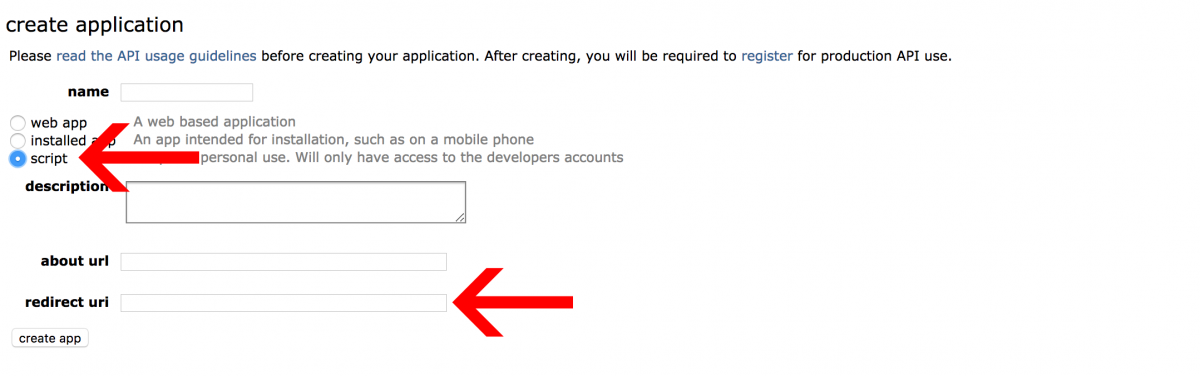
Option a name for your application and add a description for reference. Also make sure you select the "script" option and don't forget to put http://localhost:8080 in the redirect uri field. If you take any doubts, refer to Praw documentation.
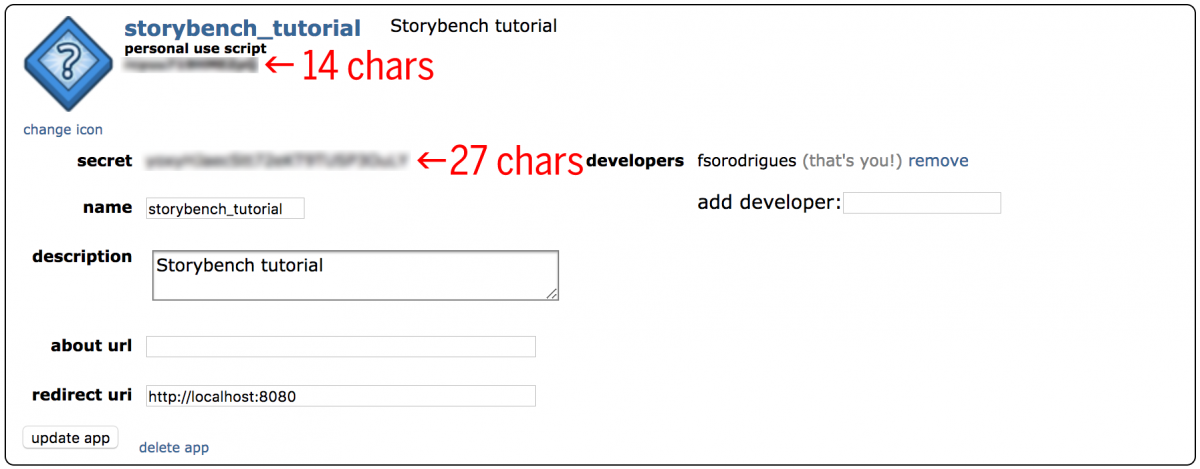
Hit create app and now you are ready to utilise the OAuth2 authorization to connect to the API and first scraping. Re-create and paste your fourteen-characterspersonal use script and 27-charactersecret key somewhere rubber. Yous application should look like this:
The "shebang line" and importing packages and modules
We will exist using but 1 of Python's built-in modules, datetime, and two 3rd-party modules, Pandas and Praw. The all-time practice is to put your imports at the meridian of the script, right after the shebang line, which starts with #!. Information technology should look like:
#! usr/bin/env python3 import praw import pandas every bit pd import datetime as dt The "shebang line" is what you see on the very beginning line of the script #! usr/bin/env python3. You only need to worry about this if you are because running the script from the command line. The shebang line is only some code that helps the computer locate python in the retention. It varies a little flake from Windows to Macs to Linux, and then replace the first line appropriately:
On Windows, the shebang line is #! python3.
On Linux, the shebang line is #! /usr/bin/python3.
Getting Reddit and subreddit instances
PRAW stands for Python Reddit API Wrapper, so information technology makes it very easy for us to access Reddit data. First we connect to Reddit by calling the praw.Reddit function and storing it in a variable. I'k calling mine reddit. You lot should pass the post-obit arguments to that part:
reddit = praw.Reddit(client_id='PERSONAL_USE_SCRIPT_14_CHARS', \ client_secret='SECRET_KEY_27_CHARS ', \ user_agent='YOUR_APP_NAME', \ username='YOUR_REDDIT_USER_NAME', \ password='YOUR_REDDIT_LOGIN_PASSWORD') From that, we utilize the same logic to become to the subreddit we want and phone call the .subreddit instance from reddit and pass it the name of the subreddit nosotros want to access. It tin be institute after "r/" in the subreddit'due south URL. I'm going to use r/Nootropics, 1 of the subreddits we used in the story.
Besides, retrieve assign that to a new variable like this:
subreddit = reddit.subreddit('Nootropics') Accessing the threads
Each subreddit has five unlike ways of organizing the topics created by redditors: .hot, .new, .controversial, .top, and .gilded. You can also use .search("SEARCH_KEYWORDS") to become merely results matching an engine search.
Permit's just grab the most upward-voted topics all-time with:
top_subreddit = subreddit.top() That will return a list-like object with the top-100 submission in r/Nootropics. Yous tin can control the size of the sample past passing a limit to .acme(), but exist aware that Reddit's request limit* is 1000, like this:
top_subreddit = subreddit.top(limit=500) *PRAW had a fairly easy work-effectually for this by querying the subreddits past date, but the endpoint that immune it is soon to be deprecated by Reddit. We will try to update this tutorial every bit presently every bit PRAW's adjacent update is released.
There is likewise a way of requesting a refresh token for those who are advanced python developers.
Parsing and downloading the data
We are right now really shut to getting the data in our hands. Our top_subreddit object has methods to return all kinds of information from each submission. You lot can bank check information technology for yourself with these unproblematic two lines:
for submission in subreddit.summit(limit=i): print(submission.title, submission.id) For the project, Aleszu and I decided to scrape this data about the topics: title, score, url, id, number of comments, date of creation, trunk text. This tin exist done very easily with a for lop merely like above, but starting time we need to create a place to store the information. On Python, that is usually done with a dictionary. Allow'southward create it with the following code:
topics_dict = { "title":[], \ "score":[], \ "id":[], "url":[], \ "comms_num": [], \ "created": [], \ "torso":[]} Now nosotros are ready to starting time scraping the information from the Reddit API. We will iterate through our top_subreddit object and append the information to our dictionary.
for submission in top_subreddit: topics_dict["title"].append(submission.title) topics_dict["score"].suspend(submission.score) topics_dict["id"].append(submission.id) topics_dict["url"].append(submission.url) topics_dict["comms_num"].append(submission.num_comments) topics_dict["created"].append(submission.created) topics_dict["body"].append(submission.selftext) Python dictionaries, still, are non very like shooting fish in a barrel for us humans to read. This is where the Pandas module comes in handy. We'll finally use it to put the data into something that looks like a spreadsheet — in Pandas, we call those Data Frames.
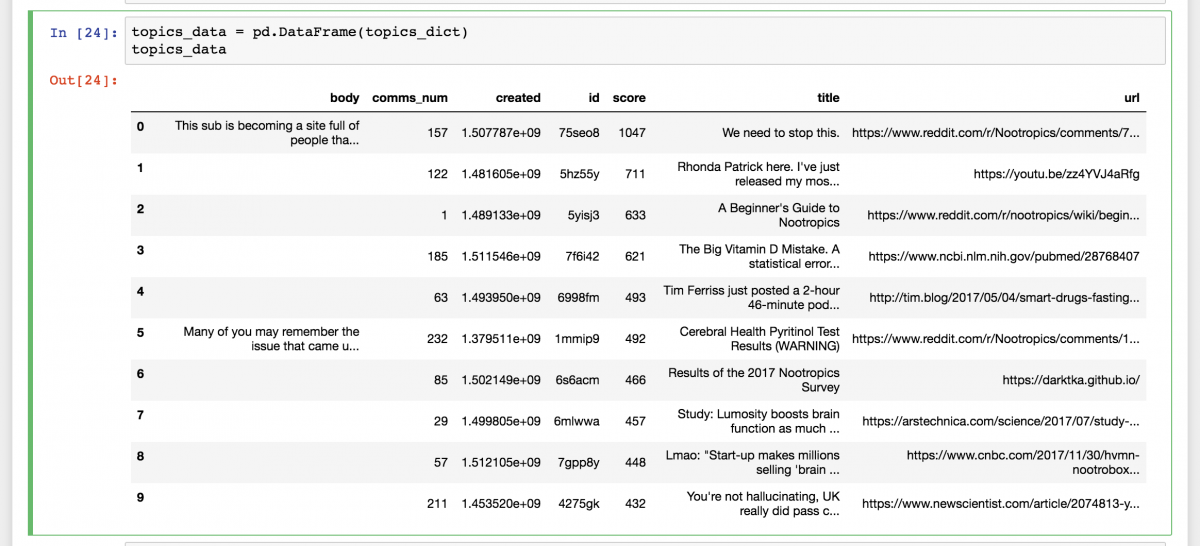
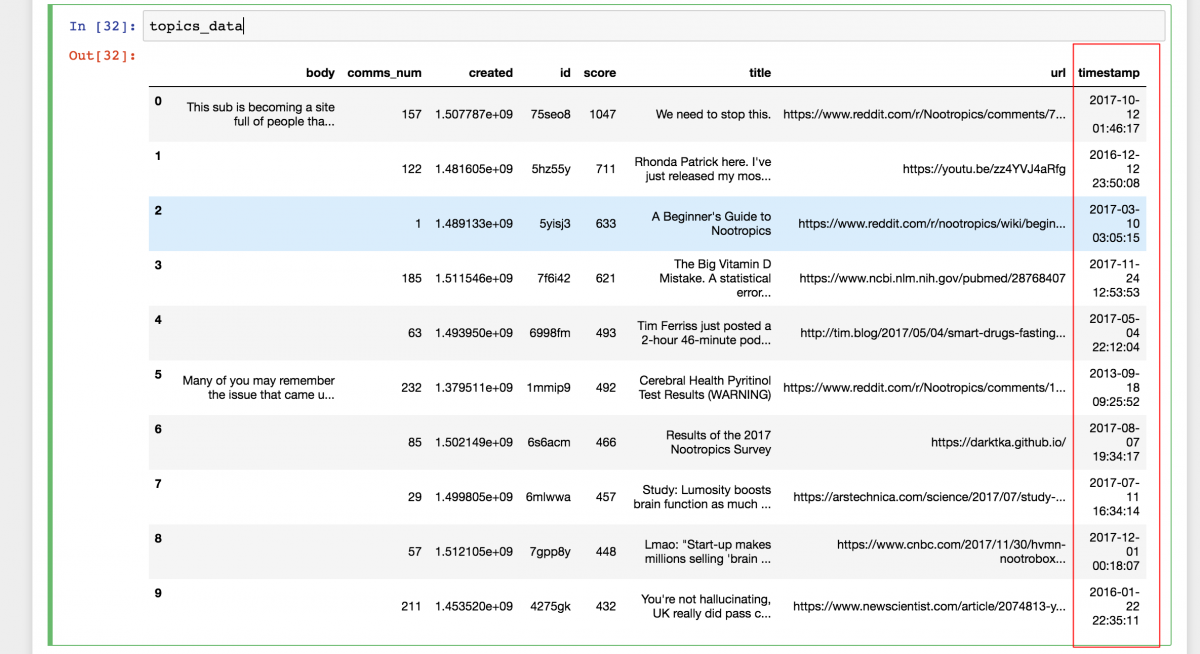
topics_data = pd.DataFrame(topics_dict) The information now looks like this:
Fixing the engagement column
Reddit uses UNIX timestamps to format date and time. Instead of manually converting all those entries, or using a site like www.unixtimestamp.com, we can easily write up a part in Python to automate that process. We define it, phone call information technology, and join the new column to dataset with the following lawmaking:
def get_date(created): render dt.datetime.fromtimestamp(created) _timestamp = topics_data["created"].apply(get_date) topics_data = topics_data.assign(timestamp = _timestamp) The dataset now has a new column that we can understand and is ready to be exported.
Exporting a CSV
Pandas makes information technology very easy for united states to create data files in various formats, including CSVs and Excel workbooks. To finish up the script, add the following to the terminate.
topics_data.to_csv('FILENAME.csv', alphabetize=Faux) That is it. Y'all scraped a subreddit for the first fourth dimension. At present, let's get run that absurd data assay and write that story.
If yous have whatever questions, ideas, thoughts, contributions, y'all can achieve me at @fsorodrigues or fsorodrigues [ at ] gmail [ dot ] com.
- Author
- Contempo Posts
![]()
Felippe is a former police educatee turned sports author and a large fan of the Olympics. He is currently a graduate student in Northeastern's Media Innovation program.
![]()
Source: https://www.storybench.org/how-to-scrape-reddit-with-python/
0 Response to "How Do You Know if Something Is Getting Down Voted on Reddit"
Post a Comment